옵티마이저 (최적화 함수)
2021. 5. 10. 07:22ㆍ기본 딥러닝
ㅇ 옵티마이저란 딥러닝, 머신러닝 학습 프로세스에서 실제로 파라미터를 갱신시키는 부분을 의미.
실제 가중치 변화를 주는 부분
ㅇ 손실함수를 기준으로 경사를 하강하며 오차를 수정
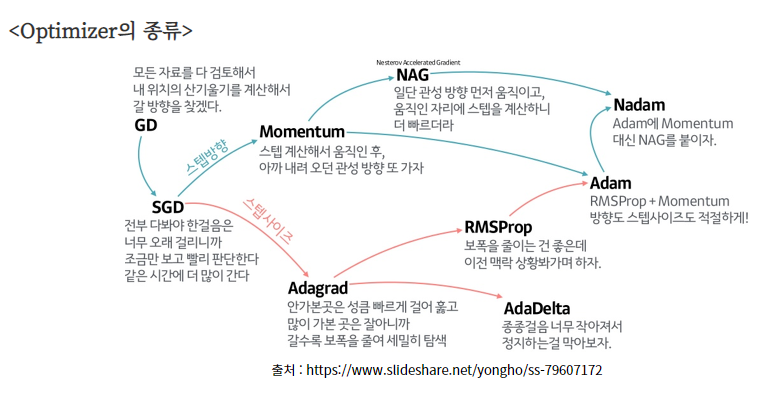
1. Gradient descent(GD)
- 가장 기본이 되는 옵티마이저 알고리즘으로 경사를 따라 내려가면서 손실이 0이 되게 가중치를 업데이트 시킴

2. Stochastic gradient decent(SGD)
- full batch가 아닌 mini batch로 학습 진행
- 빠르게 mini batch별로 학습하면서 기울기를 수정

3. Momentum
- 현재 batch로만 학습하는 것이 아니라 이전의 batch 학습결과도 반영
(현재 batch에 의해 학습이 크게 바뀌지 않게하기 위해 이전의 학습결과를 보통 0.9반영하고 현재 batch는 0.1만 반영)
4. RMSprop
- Momentum과 반대로 현재 batch에 의한 최신 기울기가 크게 반영되도록 한다.
- 즉, 과거 가중치에 큰 변동사항이 있었어도 현재 batch에서 기울기가 완만하면 학습률을 높인다.
5. Adam
- Momentum과 RMSprop을 융합한 방법
'기본 딥러닝' 카테고리의 다른 글
| Batch Normalization (배치 정규화) (0) | 2021.05.29 |
|---|---|
| Regularization과 Normalization (0) | 2021.05.29 |
| 오버피팅 해결 방법 (0) | 2021.05.26 |
| 활성화 함수 (0) | 2021.05.10 |
| 손실함수 (0) | 2021.05.08 |