2023. 3. 1. 02:34ㆍ데이터 사이언스/모델링 결과 확인
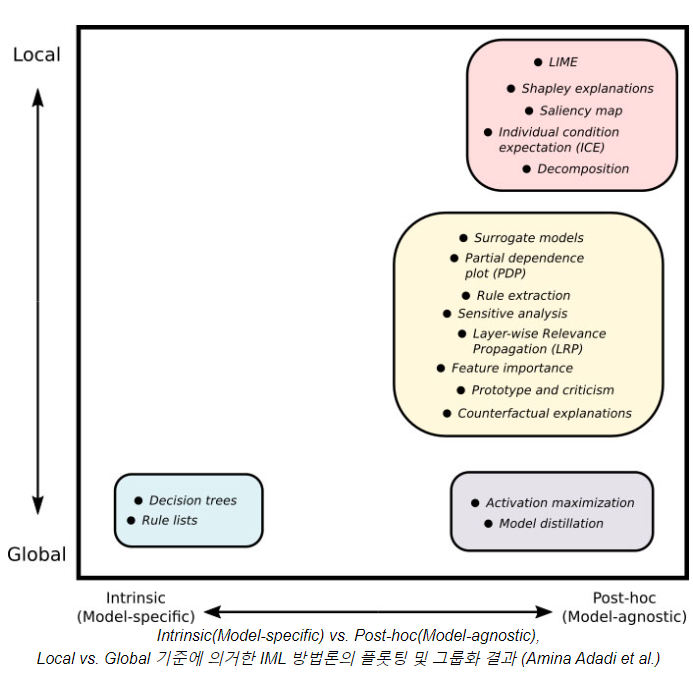
보통 intrinsic(model-specific)한 IML 방법은 그 자체가 예측 및 설명 모두를 위해 직접적으로 사용되는 경우는 드물며, 그 대신 신경망과 같이 복잡성이 높은 머신러닝 모델을 예측을 위해 먼저 사용한 뒤, 여기에 post-hoc(model-agnostic)한 IML 방법을 부가적으로 적용하는 방식이 많이 채택됨. 또, post-hoc한 IML 방법들 중 global한 것보다는 local에 가까운 방법들이 더 많이 보고되었는데, 이는 복잡성이 높은 머신러닝 모델에 대한 효과적인 설명을 위해 국소적으로나마 그럴싸한 설명을 제시할 수 있도록 하는 데 집중한 결과로 볼 수 있음
ㅇ Partial Dependence Plot (PDP)
- PDP는 관심 대상인 변수와 Target 간에 어떠한 관계가 있는지 플랏으로 나타내어 확인하는 Global 방법
- 예측값들을 평균낸 값을 가지고 플롯을 그림. 그렇기 때문에, PDP는 특정 feature의 평균 영향력을 본 것.
- 다만, 특정 변수의 평균에 대한 영향력을 보기 때문에 모든 변수간의 교호작용을 파악하기 힘듦
- 또한, 변수의 cardinality가 클 때 연산량이 너무 많아진다는 점과 변수 간 상관성이 높을 때, 비정상적인 개체를 생성할 수 있다는 것이 단점
(참고 : https://soohee410.github.io/iml_pdp)
ㅇ Individual Condition Expectation (ICE)
- 평균을 내지 않고 모든 선을 그려버리는 것이 ICE Plot이며, Local 방법
- 모든 선을 그리기 때문에 교호작용 파악 가능하다는 것이 장점
- 그러나, 변수의 cardinality가 클 때 연산량이 너무 많아진다는 점과 변수 간 상관성이 높을 때, 비정상적인 개체를 생성할 수 있다는 것이 단점
- 이 외에, 샘플 수가 많으면 사실 선이 너무 많아지면서 플롯이 지저분해짐. 따라서 샘플 수가 많을 때에는, 모든 샘플에 대한 예측값을 그리기 보다는, 일부만 추출해서 그리는 것이 더 보는 것이 좋을 것
(참고 : https://soohee410.github.io/iml_ice)
ㅇ 이외에도 하위집단 분석(Subpopulation Analysis), What-IF 분석 등을 수행하기도 함
'데이터 사이언스 > 모델링 결과 확인' 카테고리의 다른 글
| Confusion_matrix 메소드 정의 (0) | 2021.05.08 |
|---|---|
| ROC 커브 메소드 정의 (0) | 2021.05.08 |
| 여러 지표들의 결과를 한 눈에 정리해주는 메소드 (0) | 2021.05.08 |