2021. 3. 3. 18:46ㆍ자연어 처리/LSTM
IBM에서 전화를 통한 비대면 영업 시 잠재 고객을 파악하기 위해 BANT라는 지표를 만들었다.
BANT란 Budget, Authority, Needs, Timeline으로 제품에 대한 예산, 담당자, 니즈, 예상 시기를 나타낸다.
현재까지는 사람이 직접 콜을 듣고 평가했다면, 해당 글에서는 LSTM이라는 Deep Learning 기법을 통해 사람이 직접 콜을 듣고 엑셀을 통해 전사한 파일을 가지고 학습하여 BANT를 자동 분류하였다. (전사 파일 전처리 과정은 생략)
이러한 학습 결과는 영업 콜에서 STT(SOUND TO TEXT)를 통해 나온 문장을 분석하는데 활용된다.
우선 필요한 라이브러리를 import 한다

나중에 불용어 처리를 위한 형태소 분석으로는 mecab을 사용하였다.

LSTM 모델링을 위해 모듈 import

해당 프로젝트에서는 분류에 더 용이하기 위해 BANT를 하위 카테고리 키워드들로 세분화 하였었다. 이 부분은 코딩을 통해 BANT로 다시 바꿔 주었다. 코드에서는 B는 0, A는 1, N은 2, T는 3, 해당사항 없음은 4로 처리하였다.
Budget - 예산
Authority - 담당자
Needs - 개인관심, 관심, 고려, 구매, 문의, 요청, 재연락
Timeline - 시기
이러한 카테고리들은 '클라우드 서비스를 구매하고 싶어요' 라는 문장이 있을때 '구매' 라는 하위 카테고리에 해당된다.

학습하는데 사용될 전처리한 데이터셋 형태

해당사항 없음을 포함한 BANT 빈도는 당연히 해당사항 없음이 제일 높고, N, A, T 순으로 높다. B는 거의 없다고 봐도 무방하다. (해당 전사데이터에서는 B에 관한 내용이 없다)

학습 및 테스트를 하기 위해 데이터 분류 (층화 추출 사용)


불필요한 불용어는 제거. corpos_df_train은 sample_set으로, corpos_df_test는 result로 변수명 바꿔서 진행
불용어 제거 후 추출한 빈도수는 향후 하이퍼 파라미터 조정하는데 쓰임
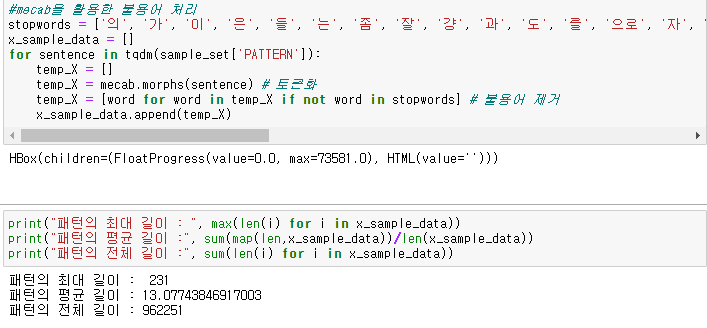

불용어 제거 후 결과 예시

불용어 제거 후 학습 및 테스트 데이터 인코딩
추출된 글자들을 컴퓨터가 이해할 수 있게 인코딩 해줘야 한다.
max_words는 데이터셋에서 가장 빈도 높은 몇개의 단어만 사용할지 선택하는 것


학습 및 테스트 데이터 셋에 대해 라벨로 사용되는 BANT 값도 인코딩을 해줘야 한다.
라벨 값의 빈도 또한 당연히 분류한 학습 및 테스트 데이터 셋의 개수와 같아야 한다.
모듈을 사용할 수 도 있지만 짧기에 직접 만들었다.


인코딩이 끝났다면 모델 적용을 해야한다. 해당 글에서는 LSTM을 사용하였다.
모델에 대한 설명은 다른 자료를 참고하며, 가벼운 모델을 사용하였다.
모델을 돌리기 전에 우선 pad_sequences를 해줘야 하는데, 이는 지정해준 max_len에서 인코딩된 글자가 있으면 해당되는 숫자를 넣어주고 없으면 0값으로 바꿔 array형태로 나열한다.
불용어 제거 후 추출한 빈도 수 중 가장 긴 문장이 231 이므로 max_len은 230으로 지정했다.

LSTM을 적용할 때, 오버피팅을 방지하고 싶으면 DROP OUT이나 양방향 LSTM을 사용하면 도움이 된다.
결과가 무조건 좋아지는 것은 아니니 시험을 해봐야 안다.

학습을 돌리기 위해 input 데이터에서의 훈련 데이터와 테스트데이터, 라벨링 데이터에서의 훈련 데이터와 테스트데이터로 나누었다.

옵티마이저는 rmsprop을 이용하였으나 adam도 시도해 보아야 한다.
loss는 categorical_crossentropy 사용, metrics은 정확도를 사용하였다.
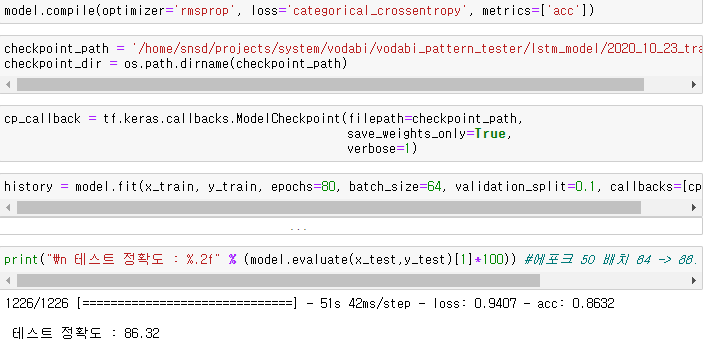
callbacks는 도중에 나오는 과정을 저장하기 위함이며, 에포크는 80, 배치 사이즈는 64, 검증 데이터는 10%를 사용하였다. 필요 시 early stopping을 사용하여 과적합을 방지하여도 좋다.
BANT만 측정하면 정확도가 99%정도 나온다.
해당 그림에는 빈 값을 포함했을 때 측정한 결과라 86%가 나왔는데, 전사데이터를 사람이 작업하면서 미 기입한 부분도 많기 때문에 이정도 결과는 준수하다고 판단된다.
해당 글에서는 정확도만 판단했지만, 데이터가 imbalance할 경우 f1 스코어 및 recall, precision 모두 고려해야 한다.
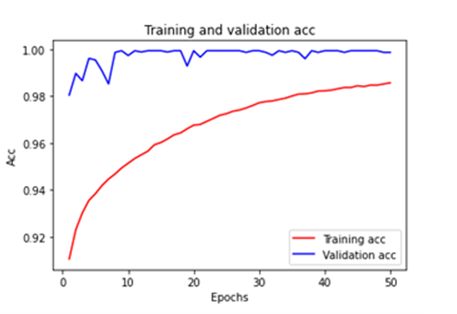
정확도와 LOSS 그래프를 통해 오버피팅인지 아닌지 확인 후 필요 시 하이퍼 파라미터를 조정하여 다시 모델을 돌린다



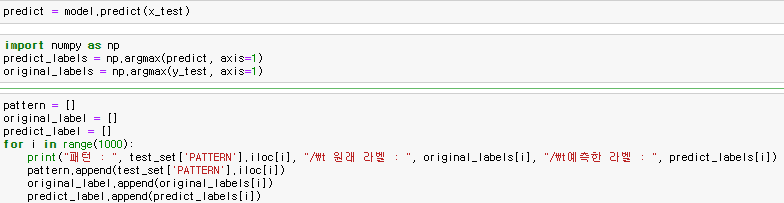
훈련 결과와 테스트 결과를 직접 눈으로 비교해 볼 수도 있다.

이상 LSTM을 통한 비정형 데이터 분류 작업에 대해 알아보았다.